

无论是甲方还是一方都需要面对大量日志处理的情况,之前分析的时候用基本的shell命令进行处理,但是面对大量数据的时候则有些力不从心,而且面对纯文字也不大直观。后来有人推荐了ELK,最近ELK升级到了版本五。E, L, K三大组件统一了版本号,花了一段时间总算搭好了。
0×01 安装java
ELK需要最新的java1.8.CentOS自带了openjdk1.7,删了重新安装Oracle Java
yum remove java
然后从oracle官网(http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html)下载java的源码包
mkdir /usr/java tar -zxvf jdk-8u131-linux-x64.tar.gz -C /usr/java/
编辑/etc/profile
JAVA_HOME=/usr/java/jdk1.8.0_131 JRE_HOME=/usr/java/jdk1.8.0_131/jre PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin CLASSPATH=:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib export PATH=$PATH:$JAVA_HOME:$JRE_HOME:$CLASSPATH
创建java的软连接
cd /usr/bin ln -s /usr/java/jdk1.8.0_131/bin/java java
2. 安装elasticsearch
去elk官网下载elasticsearch的rpm包,
直接安装
rpm -ivh elasticsearch-5.5.0.rpm
启动测试
/etc/init.d/elasticsearch start
如图,安装成功
清空elasticsearch的数据
curl -XDELETE \'http://127.0.0.1:9200/logstash-*\'
配置一下权限
cd /var/lib
chmod -R 777 logstash
3. 安装kibana
还是从官网下载kibana的二进制包
rpm -ivh kibana-5.5.0-x86_64.rpm
启动
/etc/init.d/kibana start
如图所示,kibaba也安装成功了,现在kibana只能从本地访问,为了方便调试,利用nginx做一下反向代理
yum install nginx
#/etc/nginx/conf.d/default.conf
server {
listen 80;
location / {
proxy_pass [http://localhost:5601](http://localhost:5601);
}
}
4. 安装logstash
安装logstash和之前的步骤一样,但是logstash是没有独立的守护服务的
安装后的路径
/usr/share/logstash/
创建config的软连接
cd /usr/share/logstash ln -s /etc/logstash ./config
Logstash配置文件是JSON格式,放在/etc/logstash/conf.d 。 该配置由三个部分组成:输入,过滤器和输出。
其中input和output是必须的,logstash由一个e参数,可以在终端调试配置文件
最简单的输入输出
/usr/share/logstash/bin# ./logstash -e \'input { stdin { } } output { stdout {} }\'
采用格式化输出
logstash -e \'input { stdin { } } output { stdout { codec => rubydebug } }\'
这边,我们是从终端输入,同时也从终端输出,但在实际状况中几乎不可能这么做,那先打通输出环节吧,把输出的内容发送到
Elasticsearch
首先启动Elasticsearch,确保9200端口开着,前边已经启动了。然后执行
./logstash -e \'input { stdin { } } output { elasticsearch { hosts => localhost } }\'
确认一下
curl \'http://localhost:9200/_search?pretty\'
logstash的e参数调试是很方便,但是内容多的话就不方便了,logstash还有一个f参数,用来从配置文件中读取信息,简单示例
#logstash_simple.conf
input { stdin { } }
output {
elasticsearch { hosts => localhost }
}
# ./logstash -f ../config/logstash_simple.conf

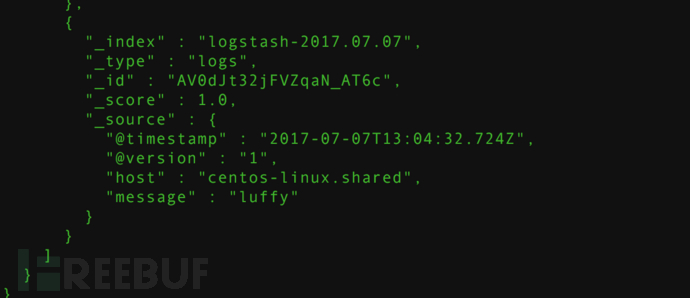
然后说一下过滤器
#logstash.conf
input { stdin {} }
filter {
grok {
match => [\"message\", \"%{COMBINEDAPACHELOG}\"]
}
}
output {
elasticsearch { hosts => localhost }
}
filter 以何种规则从字符串中提取出结构化的信息,grok是logstash里的一款插件,可以使用正则表达式匹配日志,上文中的%{COMBINEDAPACHELOG}是内置的正则,用来匹配apache access日志.
测试信息
127.0.0.1 - - [11/Dec/2013:00:01:45 -0800] \"GET /xampp/status.php HTTP/1.1\" 200 3891 \"http://cadenza/xampp/navi.php\" \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:25.0) Gecko/20100101 Firefox/25.0\"
curl \'http://localhost:9200/_search?pretty\'
分析本地的apache日志文件
首先启动elasticsearch
/etc/init.d/elasticsearch start
然后创建logstash的json文件
#logstash_apache.conf
input {
file {
path => \"/tmp/access.log\"
type => \"apache\"
start_position => \"beginning\"
}
}
filter {
grok {
match => {
\"message\" => \"%{COMBINEDAPACHELOG}\"
}
}
date {
match => [ \"timestamp\" , \"dd/MMM/YYYY:HH:mm:ss Z\"]
}
}
output {
elasticsearch { hosts => localhost }
}
启动logstash
./logstash -f ../config/logstash_apache.conf
根据日志的时间修改一下时间段
然后是我最喜欢的功能,基于IP的地理位置显示
